Understanding the Ethereum Yellow Paper
A complete overview of the Ethereum Yellow Paper, explained in an understandable way.

Disclaimer:
- I am not an expert on Ethereum. I’m just a curious person who likes to learn about new things. If you find any mistakes, please let me know say hi on Twitter.
- I am also not the original person who wrote all these stuff. In the journey of trying to understand the Ethereum protocol and clients (geth, reth, lighthouse, prysm, …), I just found and copied these content from all over the internet (from many articles by many authors) and put it here for my own reference. If you are the original authors and want me to take it down, please let me know.
Ok, let’s get started!
There are lots of different descriptions of Ethereum floating around on the internet. It’s a world computer, a game-changing technology, and the foundation for our digital future. These descriptions sound nice, but they don’t help us understand what Ethereum is, much less how it works.
That’s where this post comes in. In order to really understand what’s going on, I’m going to break down every section of the Ethereum Yellow Paper (excluding the appendix, that would take too long). I’ll skip over the more mathy, technical portions of the yellow paper. But don’t worry—if you get through this, you’ll have a thorough understanding of what Ethereum is and how it works. Let’s get started.
First, let’s answer a simple question: what is the Yellow Paper talking about? Let’s take a look at the conclusion to get an answer:
We have introduced, discussed and formally defined the protocol of Ethereum. Through this protocol the reader may implement a node on the Ethereum network and join others in a decentralised secure social operating system.
In other words, the Ethereum Yellow Paper describes a protocol called Ethereum. Implementations of the protocol are called clients - anyone can run a client to create a node on the Ethereum network, and join all the other nodes that are running an implementation of the Ethereum protocol.
Note: people use the word “Ethereum” to describe both the protocol and the implementation. For the rest of this post, we’ll use the word “Ethereum” to refer to the implementation.
Alright, so this paper describes the Ethereum protocol. What does the implementation of the protocol do? To answer that question, we’ll return to the abstract and introduction:
The blockchain paradigm when coupled with cryptographically-secured transactions has demonstrated its utility through a number of projects, with Bitcoin being one of the most notable ones. Each such project can be seen as a simple application on a decentralised, but singleton, compute resource. We can call this paradigm a transactional singleton machine with shared-state.
[Bitcoin] can be said to be a very specialised version of a cryptographically secure, transaction-based state machine.
Ethereum is a project which attempts to build the generalised technology; technology on which all transaction- based state machine concepts may be built.
The simple explanation of this is that Ethereum is a bunch of computers that run transactions in order to update some shared state. Sending ETH to a friend? That’s a transaction, and it changes the state by decrementing and incrementing the sender’s and receiver’s account balances. Calling the method of a smart contract? That’s a transaction, and it can update the state using a programming language called Solidity. “Shared” is a keyword here—even though a bunch of different computers are doing this, they all agree on the same state.
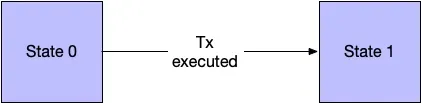
Ethereum is basically just a bunch of computers doing this over and over again.
That was a simplified explanation. Now let’s break this down in a bit more detail.
- Ethereum is cryptographically secure. Valid transactions require the cryptographic signature of the sender. Blocks require proof of work, a cryptographic proof that shows a certain amount of computational effort has been spent. All in all, this means it is nearly impossible for attackers to maliciously alter the blockchain (e.g. create fake transactions or delete transactions). The practical result of this is that people can trust the data on the blockchain.
- Ethereum is a transaction-based state machine. It transitions from one state to the next by running transactions.
- Ethereum has shared state. Even though the Ethereum network is made up of many computers, they all maintain the same state, and function as a single virtual computer. This is why Ethereum is sometimes called a “world computer”.
- Ethereum is a generalized technology. Bitcoin implements the same model as Ethereum—it is also a cryptographically secured, transaction-based state machine. However, Bitcoin’s only purpose is to transfer value. You can build lots of different things on top of Ethereum, including but not limited to token systems (ERC20 tokens), identity systems (ENS), DAOs, NFTs, etc.
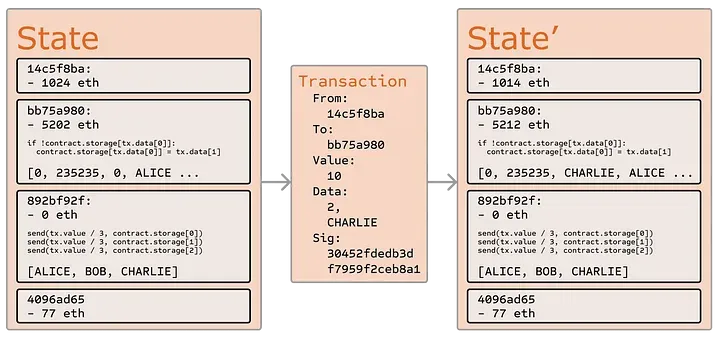
Similar to the above diagram, but much more complicated! Ethereum is a transaction-based state machine. This means all the nodes in the Ethereum network (the computers running an implementation of the Ethereum protocol) are continuously running transactions in order to update some shared state.
1.1 Driving Factors
What’s the point of this whole thing? Here’s how the paper phrases it:
one key goal is to facilitate transactions between consenting individuals who would otherwise have no means to trust one another.
In other words, Ethereum lets people write code to facilitate transactions between untrusted individuals.
Here’s a simple example. Let’s say Alice and Bob want to make a bet on the Super Bowl. Let’s assume they don’t trust each other, and can’t find a trusted middleman to facilitate the bet. In order to guarantee the bet gets carried out, here’s what they do. First, they write a smart contract that lets them each deposit $100. The smart contract has a method called rewardWinner. Either Alice or Bob can call this function on the day after the Super Bowl. If the home team wins, the contract gives $200 to Alice. Otherwise, the contract gives $200 to Bob.
Couldn’t you also make a traditional website that solves this problem? Why do we need Ethereum? It’s possible, but it would be more complicated to build (e.g. maybe Stripe would be used to handle payouts), it would require users to supply more information (e.g. bank info), and be harder to verify the code. Put another way, since the ability to exchange value is baked into Solidity, the smart contract would be simpler, smaller, and easier to verify. Furthermore, with traditional software products, even if it’s open source, there is likely a centralized organization that has some special access to the data. E.g. an app can be open sourced, but if it uses a Postgres database, the admin can modify the data however they want.
The paper also mentions that using Ethereum to facilitate transactions has two major advantages to traditional systems:
- “Incorruptibility of judgement” — why rely on a human judge to be impartial when you can rely on cold hard code?
- “Transparency” — you can look at the source code and examine the transactions themselves (e.g. on Etherscan) to see exactly what happened and why.
Finally, the paper says this:
Overall, we wish to provide a system such that users can be guaranteed that no matter with which other individuals, systems or organisations they interact, they can do so with absolute confidence in the possible outcomes and how those outcomes might come about.
I’m actually a bit skeptical of this lofty goal.
1.2 Previous Work
There’s not too much to discuss here, but I like this quote:
Around the 1990s it became clear that algorithmic enforcement of agreements could become a significant force in human cooperation. Though no specific system was proposed to implement such a system, it was proposed that the future of law would be heavily affected by such systems. In this light, Ethereum may be seen as a general implementation of such a crypto-law system.
This gives us yet another description of Ethereum—it allows for “algorithmic enforcement of agreements.”
2. The Blockchain Paradigm
This section dives deeper into what a blockchain actually is. First, let’s review what Ethereum is:
Ethereum, taken as a whole, can be viewed as a transaction-based state machine: we begin with a genesis state and incrementally execute transactions to morph it into some current state. It is this current state which we accept as the canonical “version” of the world of Ethereum.
The state can include such information as account balances, reputations, trust arrangements, data pertaining to information of the physical world; in short, anything that can currently be represented by a computer is admissible.
This should be familiar—we covered it in the previous section. Note that unlike Bitcoin, which just stores how much Bitcoin everyone has, Ethereum can store arbitrary state.
In order to get from one state to the next, Ethereum executes transactions.

The formal definition of transaction execution.
Note that executing a transaction can involve “arbitrary computation,” i.e. it can involve running some arbitrary Solidity code. This is what makes Ethereum so powerful—it’s a generalized technology that empowers developers.
Ok, we’ve covered transactions. What about blocks? And what about chains of blocks? Simply put, blocks are just a bunch of transactions that are grouped together (it’s actually a little more complicated, we’ll go into more detail in section 4). Each block also refers to the previous block by its hash, forming a chain of blocks. Here’s how the paper phrases it:
Transactions are collated into blocks; blocks are chained together using a cryptographic hash as a means of reference. Blocks function as a journal, recording a series of transactions together with the previous block and an identifier for the final state (though do not store the final state itself — that would be far too big).
That last sentence is interesting—the blockchain does not actually store Ethereum’s state, e.g. what your account balance is. It is up to the computers that implement the Ethereum protocol to store the state as a Merkle Patricia tree. We’ll talk more about this in section 4.
How do new blocks get created? People called miners run programs that batch transactions into blocks. For a block to be valid, it must include proof of work, i.e. it must include a value that satisfies a mathematical condition. The only way to calculate the value is by brute force.
If you’re reading this, I assume you already know what proof of work is. But just in case, here’s a simple explanation. Proof of work just means you can prove you spent a certain amount of computational energy. The value (called a nonce) mentioned above fits the bill because the only way to calculate it is brute force, i.e. enumerating all possibilities, i.e. spending computational energy. Proof of work makes the blockchain secure, because it would cost a large amount of energy (which is expensive) in order to mount certain attacks.
2.1 Value
So, why do miners spend all this energy mining new blocks! It’s simple—because they get rewarded! Ether, or ETH, is the currency of the Ethereum blockchain, and is used to reward miners. You also need to pay ETH if you want to run code on the blockchain. Just like we have dollars and cents, there are different denominations of ETH.

Each denomination is named after a well-known person in the crypto space.
2.2 Which History?
We said above that blocks form a chain. That’s actually not entirely true—anyone has the opportunity to create a new block on some older pre-existing block, which means a tree of blocks get formed.
Since there’s a tree of blocks, we need some way to obtain consensus about which path of the tree is the “right” one. Turns out it’s pretty simple—the path with the most computational work put into it is chosen (basically, the longest path), and this is what is referred to as the blockchain.
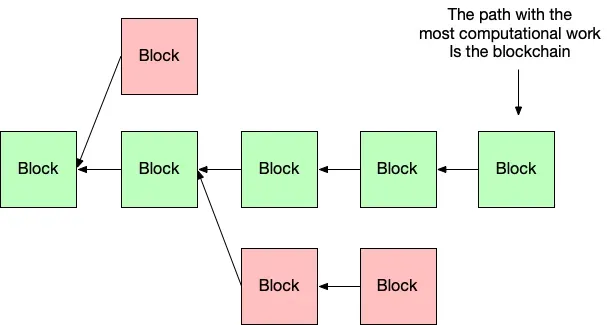
There is a tree of blocks. The path through the tree with the most computational work is the blockchain.
3. Conventions
This section defines a bunch of symbols for the math portions of the paper. No need to cover this.
4. Blocks, State, and Transactions
This is where things start to get really interesting! This section defines blocks, state, and transactions in detail.
4.1 World State
Let’s start with state.
The world state (state), is a mapping between addresses (160-bit identifiers) and account states (a data structure serialised as RLP, see Appendix B). Though not stored on the blockchain, it is assumed that the implementation will maintain this mapping in a modified Merkle Patricia tree (trie, see Appendix D). The trie requires a simple database backend that maintains a mapping of byte arrays to byte arrays; we name this underlying database the state database. This has a number of benefits; firstly the root node of this structure is cryptographically dependent on all internal data and as such its hash can be used as a secure identity for the entire system state. Secondly, being an immutable data structure, it allows any previous state (whose root hash is known) to be recalled by simply altering the root hash accordingly. Since we store all such root hashes in the blockchain, we are able to trivially revert to old states.
This whole section is really interesting, so let’s break it down bit-by-bit. The first part is simple—the world state is a key-value store where the keys are addresses and the values are account states.
Next, the paper says that the state is not stored on the blockchain, because it’s too much data to store (this was mentioned in section 2). So, where is it stored? It’s assumed that nodes in the Ethereum network will store this key-value store in a Merkle Patricia tree.
Why a Merkle Patricia tree? The paper tells us: “the root node of this structure is cryptographically dependent on all internal data and as such its hash can be used as a secure identity for the entire system state.” In simple terms, if you change the data stored in the tree, the root hash will also change. Since Ethereum nodes store Merkle Patricia trees, the blockchain can just store the root hash, which lets nodes validate the state of newly mined blocks. To fully understand this, you need to understand Merkle Patricia trees more. I recommend these three articles (one, two, three). For now, here’s a brief explanation.
This diagram depicts blocks (stored on the blockchain) and the Merkle Patricia tree (stored off-chain by nodes). The tree maps keys to value—a given key tells how you to traverse the tree, and values are at the leaves. In order to be more space efficient, nodes don’t store a separate state tree for each block. Instead, for each block, nodes store only the updated values, and refer to the previous immutable trees for the rest of the state.
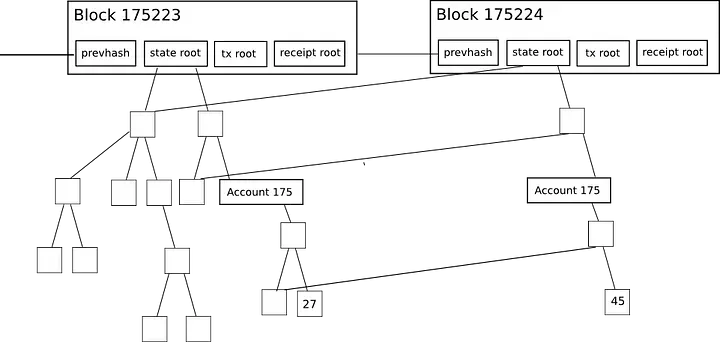
With this structure in mind, it’s easier to understand the second benefit of Merkle trees:
Secondly, being an immutable data structure, it allows any previous state (whose root hash is known) to be recalled by simply altering the root hash accordingly. Since we store all such root hashes in the blockchain, we are able to trivially revert to old states.
Since the tree is immutable, if a node wants to check the state for a previous block, they can just check the block’s root hash and revert to the corresponding state tree.
Phew, that was complicated. Let’s recap:
- The world state is a key-value store, where the keys are addresses and the values are account states.
- Nodes store the world state as a Merkle Patricia tree.
- The blockchain stores the root hash of this tree in each block header.
Let’s talk about accounts now. Recall from above: “The world state is a mapping between addresses (160-bit identifiers) and account states (a data structure serialised as RLP, see Appendix B).” So, what are account states?
Each account has four parts:
- nonce. For non-contract accounts, it’s the number of transactions sent from the address. For contract accounts, it’s the number of contract creations made by the account.
- balance. Pretty self explanatory, it’s how much ETH the account has.
- storageRoot. This is the root hash of yet another Merkle Patricia tree. This tree stores data specific to the account, and is nested in the top-level “world state” Merkle Patricia tree.
- codeHash. This differentiates contract accounts from external accounts (i.e. accounts owned by real people). If this is the hash of the empty string, the account is an external one.
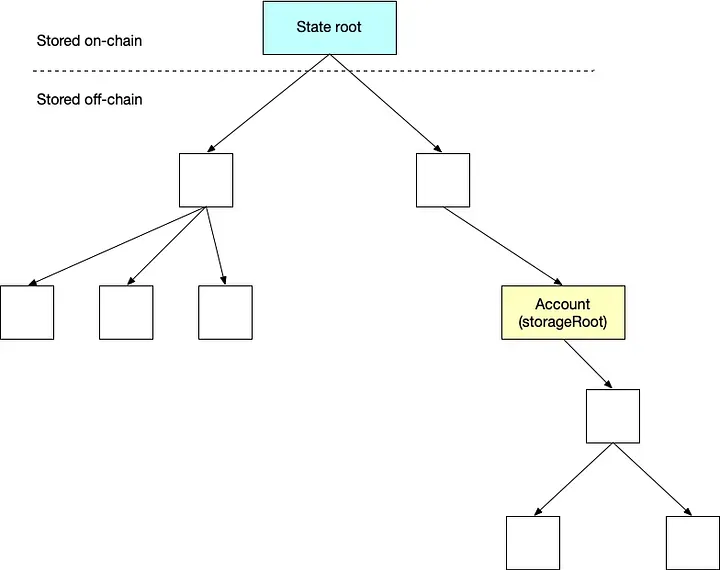
The root hash of the state tree is stored on-chain in a block header. The state tree maps addresses to accounts. Each account has a storageRoot value, which refers to yet another Merkle Patricia tree.
4.2 The Transaction
Let’s move onto transactions! Remember from section 2 that a transaction is a bridge between two states. In order to transition from one state to the next, a transaction gets executed. The appendix has a good definition for a transaction:
Transaction: A piece of data, signed by an External Actor. It represents either a Message or a new Autonomous Object. Transactions are recorded into each block of the blockchain.
This section says the following:
There are two types of transactions: those which result in message calls and those which result in the creation of new accounts with associated code
For the definition of a message call, we can also consult the appendix:
Message Call: The act of passing a message from one Account to another. If the destination account is associated with non-empty EVM Code, then the VM will be started with the state of said Object and the Message acted upon. If the message sender is an Autonomous Object, then the Call passes any data returned from the VM operation.
Ok, let’s piece this together. A transaction is initiated and signed by an external actor (e.g. you!). This distinction is necessary because message calls, which are basically the same as transactions, can come from either external actors or smart contracts.
There are two types of transactions.
- Transactions which result in message calls are the more common type of transaction. They include transactions where you send money to someone else, and transactions where you call the method of some smart contract.
- Contract creation transactions. This is pretty self-explanatory… these transactions create contracts. Note that contracts can also be created within another contract. For example, let’s say you call method
createRainof a smart contract calledCloud. This method creates a newRaincontract. This transaction is still a message call transaction, even though a new contract was created, because the contract creation was initiated from within a contract. This is a bit confusing, but practically it’s not very important.
Each transaction contains the following fields. Basically, these fields tell the transaction executor what to do.
- nonce: Number of transactions sent by the sender.
- gasPrice: The number of Wei to be paid per unit of gas for all computation costs incurred by executing the transaction (Note: EIP 1559 changed this).
- gasLimit: A scalar value equal to the maximum amount of gas that should be used in executing this transaction. This is paid up-front, before any computation is done and may not be increased later (Note: EIP 1559 changed this).
- to: The 160-bit address of the message call’s recipient or, for a contract creation transaction, an empty byte array.
- value: A scalar value equal to the number of Wei to be transferred to the message call’s recipient or, in the case of contract creation, as an endowment to the newly created account.
- v, r, s: Values corresponding to the signature of the transaction and used to determine the sender of the transaction.

A simplified depiction of a transaction from the Ethereum whitepaper.
A contract creation transaction contains one additional field called init. This is an EVM code fragment that when executed, returns the actual code associated with the smart contract (e.g. the code that gets run when you call the smart contract). Think of it like this:
// init codereturn `
contract Foo {
...
}
`;A message call transaction also contains an additional field, called data. This is an unlimited size byte array specifying the input data of the message call.
4.3 The Block
Each block is made up of three parts:
- The block header.
- A list of ommer block headers.
- A list of transactions.
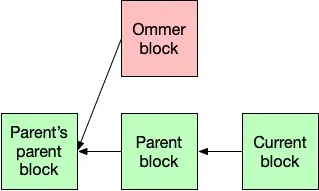
An ommer block’s parent is equal to the current block’s parent’s parent.
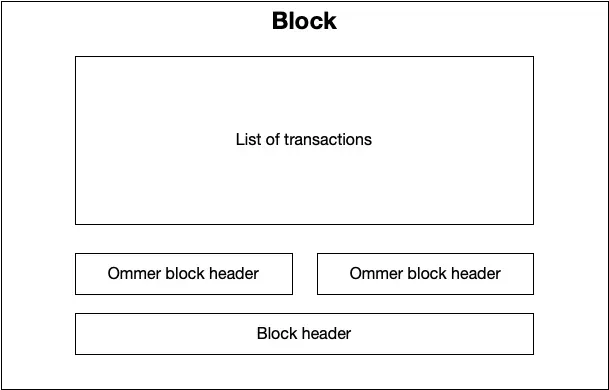
A high level diagram of a block
The block header contains a lot of important fields. Here’s the full list:
- parentHash: The Keccak 256-bit hash of the parent block’s header, in its entirety.
- ommersHash: The Keccak 256-bit hash of the ommers list portion of this block.
- beneficiary: The 160-bit address to which all fees collected from the successful mining of this block be transferred.
- stateRoot: The Keccak 256-bit hash of the root node of the state tree, after all transactions are executed and finalisations applied.
- transactionsRoot: The Keccak 256-bit hash of the root node of the trie structure populated with each transaction in the transactions list portion of the block.
- receiptsRoot: The Keccak 256-bit hash of the root node of the trie structure populated with the receipts of each transaction in the transactions list portion of the block.
- logsBloom: The Bloom filter composed from indexable information (logger address and log topics) contained in each log entry from the receipt of each transaction in the transactions list.
- difficulty: A scalar value corresponding to the difficulty level of this block. This can be calculated from the previous block’s difficulty level and the timestamp.
- number: A scalar value equal to the number of ancestor blocks. The genesis block has a number of zero.
- gasLimit: A scalar value equal to the current limit of gas expenditure per block.
- gasUsed: A scalar value equal to the total gas used in transactions in this block.
- timestamp: A scalar value equal to the reasonable output of Unix’s
time()at this block’s inception. - extraData: An arbitrary byte array containing data relevant to this block. This must be 32 bytes or fewer.
- mixHash: A 256-bit hash which, combined with the nonce, proves that a sufficient amount of computation has been carried out on this block.
- nonce: A 64-bit value which, combined with the mixHash, proves that a sufficient amount of computation has been carried out on this block.
Most of these are pretty self-explanatory, but let’s elaborate on a few of them. Notice there are three root hashes, the state root, transactions root, and receipts root. This means Ethereum nodes are responsible for storing three different Merkle Patricia trees. We covered the first tree in section 4.1, and the transactions tree is pretty self explanatory—the keys of the tree are transaction indices, and the values are transactions themselves. But what about the receipts tree?
The receipts tree’s keys are transaction indices, and the values are transaction receipts. A transaction receipt is a tuple of four items:
- The status code of the transaction.
2. The cumulative gas used in the block as of immediately after the transaction was executed.
3. The set of logs created through execution of the transaction.
4. The bloom filter of those logs.
You may have seen Solidity code like this before:
emit Transfer(address(0), to, tokenId);When this code is run as part of a transaction, a Transfer log will be added to the transaction’s set of logs. Since these logs are stored by Ethereum nodes, you’re able to query them (e.g. with ethers.js). Frontends for dapps commonly use these logs to display additional information to users. For example, OpenSea displays the activity of each NFT (minting, listing, sales).
There’s one more thing to cover in this section—block validity. For this, we’ll turn yet again to the whitepaper:
The basic block validation algorithm in Ethereum is as follows:
1. Check if the previous block referenced exists and is valid.
2. Check that the timestamp of the block is greater than that of the referenced previous block and less than 15 minutes into the future.
3. Check that the block number, difficulty, transaction root, uncle root and gas limit (various low-level Ethereum-specific concepts) are valid.
4. Check that the proof of work on the block is valid.
5. LetS[0]be the state at the end of the previous block. LetTXbe the block’s transaction list, withntransactions. For alliin0...n-1, setS[i+1] = APPLY(S[i],TX[i]). If any application returns an error, or if the total gas consumed in the block up until this point exceeds theGASLIMIT, return an error.
6. LetS_FINALbeS[n], but adding the block reward paid to the miner.
7. Check if the Merkle tree root of the stateS_FINALis equal to the final state root provided in the block header. If it is, the block is valid; otherwise, it is not valid.
The first 4 are pretty straightforward, but let’s break down 5–7. Let’s say you are a validator, and you receive a block. Recall that each block contains stateRoot, the root hash of the world state Merkle Patricia tree. In order to determine if that hash is valid, you yourself will execute all the transactions in the block, setting the initial state to the state at the end of the previous block. By doing this, you’ll end up with a new Merkle Patricia tree, and you can compare the root hash of that tree with stateRoot. If they are the same, then stateRoot is valid. Something similar must also be done for the other Merkle Patricia trees, represented by transactionsRoot and receiptsRoot.

How to determine if stateRoot is valid—run the transactions yourself!
5. Gas and payment
All computational operations in Ethereum (e.g. modifying state, adding two numbers) are subject to fees. Gas is the unit of measurement for these fees.
This section is now slightly outdated due to EIP 1559. However, the basics still stand. First, this section addresses a simple question: why is gas even a thing?
In order to avoid issues of network abuse and to sidestep the inevitable questions stemming from Turing completeness, all programmable computation in Ethereum is subject to fees.
Due to gas, someone can’t hog all the compute by running an infinite loop, because it would be prohibitively expensive.
How much gas does each transaction cost? It depends on what the transaction does, and the gas price sent by the user, since each operation (e.g. storing something in storage) requires a certain amount of gas. In total, a transaction will cost (total gas used) x (gas price) (note: EIP 1559 changed this).
6. Transaction Execution
This section looks complicated because it contains a lot of formal logic. Instead of going through all the math, we can refer to the whitepaper for a simpler explanation of transaction execution.
1. Check if the transaction is valid. If not, return an error. An example of an invalid transaction is a transaction with an invalid signature.
2. Subtract gas fees from the sender’s account, and increment their nonce. If there’s not enough gas, return an error.
3. Transfer the transaction’s value from the sender’s account to the receiver’s account.
4. If receiving account is a contract, run the code.
5. If the value transfer failed because the sender didn’t have enough money, or code execution ran out of gas, revert all state changes except the payment of gas fees to the miner’s account.
6. Otherwise, if successful, refund any remaining gas to sender, and send gas fees to the miner.
A simplified example of a transaction execution, from the whitepaper.
7. Contract Creation
This section is more-or-less covered in sections 4 and 6.
8. Message Call
This section is more-or-less covered in sections 4 and 6.
9. Execution Model
This section goes into the specifics of how a transaction gets executed. Similarly to section 6, we can refer to the whitepaper for a simpler explanation. If you actually want to implement the Ethereum protocol (best of luck!) you should read through the Yellow Paper. Otherwise, the following is enough to understand things at a high level.
From the whitepaper:
The formal execution model of EVM code is surprisingly simple. While the Ethereum virtual machine is running, its full computational state can be defined by the tuple
(block_state, transaction, message, code, memory, stack, pc, gas), whereblock_stateis the global state containing all accounts and includes balances and storage. At the start of every round of execution, the current instruction is found by taking thepc-th byte ofcode(or 0 ifpc >= len(code)), and each instruction has its own definition in terms of how it affects the tuple. For example,ADDpops two items off the stack and pushes their sum, reducesgasby 1 and incrementspcby 1, andSSTOREpops the top two items off the stack and inserts the second item into the contract’s storage at the index specified by the first item. Although there are many ways to optimize Ethereum virtual machine execution via just-in-time compilation, a basic implementation of Ethereum can be done in a few hundred lines of code.
More simply put, there is a virtual machine, the EVM, that runs EVM bytecode. Each instruction costs some gas, and modifies the tuple (block_state, transaction, message, code, memory, stack, pc, gas).
10. Blocktree to Blockchain
We covered this already in section 2.2.
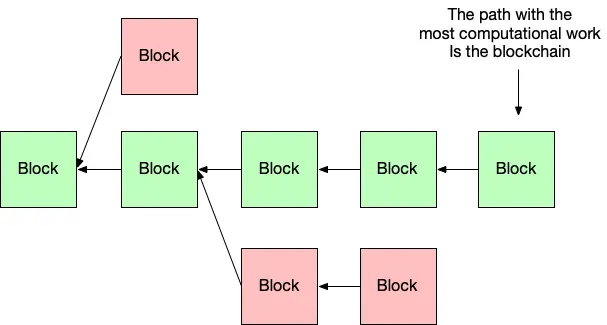
There is a tree of blocks. The path through the tree with the most computational work is the blockchain.
11. Block Finalisation
We’re getting close to the end! This section talks about the block finalisation process. Block finalisation refers to either mining a new block or validating an existing block. In each scenario, the steps are similar:
The process of finalising a block involves four stages:
(1) Validate (or, if mining, determine) ommers;
(2) validate (or, if mining, determine) transactions;
(3) apply rewards;
(4) verify (or, if mining, compute a valid) state and block nonce.
Let’s go over these steps one by one, and assume that we’re validating an existing block (as opposed to mining a new block) for simplicity’s sake. Note that we already described the block validation process in section 4.3. The steps listed here are also part of the block validation process, but most of them are not covered by the whitepaper.
Ommer validation checks the following:
- There should be a maximum of two ommer headers.
- Each ommer header should be valid (see section 4.3 for how to check block validity).
- The generation of each ommer must be at most 6. The first generation of ommer blocks are those whose parent is equal to the current block’s parent’s parent (what a mouthful).
Transaction validation checks that the gasUsed field in the block header equals the sum of all the gas each transaction used.
Reward application gives rewards to the miner and the ommers’ miners. Why reward miners of ommer blocks? Here are a couple reasons (not mentioned in the Yellow Paper):
- It reduces the effect of network lag on mining rewards, since blocks that are mined slightly later than the chosen block may still get an ommer reward.
- It incentivizes mining, since you don’t always need to be the fastest miner to get a reward. Think of it this way—if a contest only has a prize for first place, you might think it’s too hard to win and not bother joining. But if it also has second and third place prizes, maybe it’s worth giving it a shot.
State & nonce validation checks to make sure the root hash of the state tree is consistent with the actual state obtained by running the block’s transactions, and also checks that the nonce is a valid proof of work. This was covered in section 4.3.
This section also talks about proof of work. If you’re reading this, I assume you already know what proof of work is. If you don’t, I recommend this video.
We’re done! Well, not exactly—the Yellow Paper contains sections 12, 13, 14, 15, and 16. The material covered by these sections is not that important, and this post is long enough as it is, so we’ll skip them 🙃